
🦅 EagleX v2 : Soaring past LLaMA2 7B in both English and Multi-lang evals (RWKV-v5)
You have seen the teaser with the EagleX 1.7T, now its here - the definitive version of linear transformer trained past, LLaMA 2 7B.


EagleX v2 - in short
We extended the training of the previous Eagle 7B from 1.1 Trillion tokens to 2.25 Trillion tokens.
A continuation based on the original Eagle 7B model,
and the EagleX 1.7T modelTrained on 2.25 Trillion tokens across 100+ languages
Outperforms all 7B class models in multi-lingual benchmarks
Passes LLaMA2 (2T) in multiple English evals, approaches Mistral (>2T?)
We are releasing RWKV-v5 Eagle v2, licensed under Apache 2.0, which can be used personally or commercially without restrictions.
Try it online today on: recursal.ai cloud platform
Try on: our HF gradio demo
Use our reference pip inference package, or any other community inference options (Desktop App, RWKV.cpp, etc), and use it anywhere (even locally)
[Pending PR] Get support merged into Huggingface transformers!
Building on bold claims
The original EagleX 7B 1.7T, trained by Recursal AI, made history as the first sub-quadratic model, to pass llama2 7B 2T on average in English eval.
Today we are releasing the 2.25T trained variant, which furthers the gap with the llama2 model.
The following report follows the same general format of the 1.7T model release, in eval details - to make direct comparision easier.
Winning English Perplexity
We start with the basics: Perplexity. Which is the loss value against the test dataset (lower score = better), i.e. how good the model is with the next token prediction.
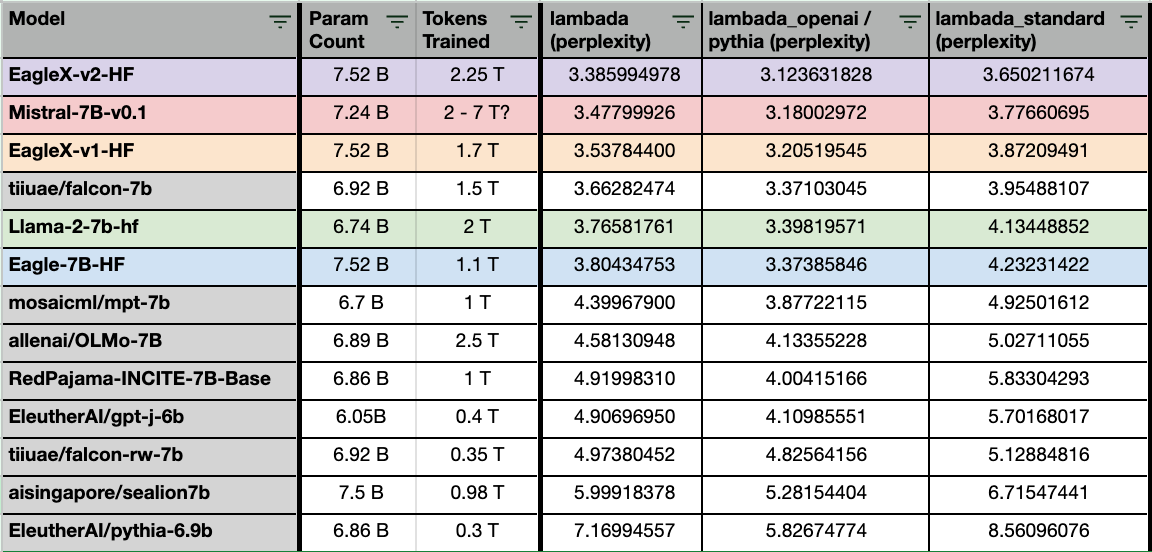
In a major first, the EagleX model - now passes mistral in perplexity. And takes the lead in the 7B model weight class.
Why do experts care about perplexity?
Eval in general can be very subjective, and opinion-driven, and commonly give mixed results. Perplexity in a way gives the TLDR summary for most experts to start with
Leading Multi-lang Perplexity & evals


EagleX maintains the lead for best-in-class multi-lingual performance, with the incremental improvements we’re making to the Eagle line of models.

Most of the tasks here are common sense reasoning tests of a wide variety of formats, across languages including 23 of the world’s most widely used languages.
For the remaining languages, we urge the community to test and judge them themselves, over 100+ languages were trained. Over time, we would want more languages to be added to evals.
Why is multi-lingual perf important?
The goal of the RWKV project & Eagle line of models is to build inclusive AI for everyone regardless of their language. Our mission is to build AI models not just made for English, but also for the 83% of the world’s population using a non-English language everyday.
Going big on eval data
As per the previous 1.7T model, we ran ALL the benchmarks in EleutherAI `lm-eval-harness`, at commit `f78e2da`, with the following limitations:
It has to be completed in under 30 minutes on 8x4090 (we were running lots of evals)
This rules out some of the rather more expensive long chain of thought evals
We excluded all the personality/alignment evals
Eval has to be executable across a wide variety of models, via lm-eval-harness
All evals are 0 shot (no 5 shot-ing an MCQ question)
We limited comparison to other models within the 7B weight class
These resulted in running 60+ major eval groups, which generated over 1,000+ data points per model. A data point count so high, that we had to drop standard error deviations, just to ensure the raw CSV file can be loaded in MacOS numbers.
21 English Evals
However, because 180+ evals are overwhelming, let’s first reduce down to 21 of the arguably most popular English evals, such as Lambada, Glue, Swag, Winogrande, TruthfulQA, MMLU:

Narrowing it down to the models that most of us actually care about - LLaMA, Mistral, EagleX, and Eagle-7b - the new EagleX v2 model outperforms LLaMA-2-7b on average across the 21 evals, and lags not far behind Mistral.

The Good
Now, let’s look at where our model is blowing the rest of the models out of the water.

First, the big stand out is the following 5 evals, in which both our 1.7T and 2.25T models beat even mistral 2T++ trained model (glue, anli, mmnli, swag), across multiple tasks focused around either contextual-based simple Q&A with common sense reasoning, or deductive logic.
PS: The jump for glue/mnli was high enough, that we needed to check the dataset specifically for contamination. Which we were not be able to find any. This jump is currently being attributed to multiple training datasets, along with data augmented / machine rewritten instruct dataset following a similar structure.

EagleX 2.25T, also performs better than LLaMA-2-7b in, lambada next token prediction and more importantly …
winograde, wnli, truthfulqa evals, which imply that the EagleX model would be applicable in RAG use cases, which are mainly contextual Q&A, with the right prompt engineering.
Strong common sense reasoning over context,
has very strong applicable use cases for multiple RAG use cases
The Mixed
Next: the eval sets with mixed results.
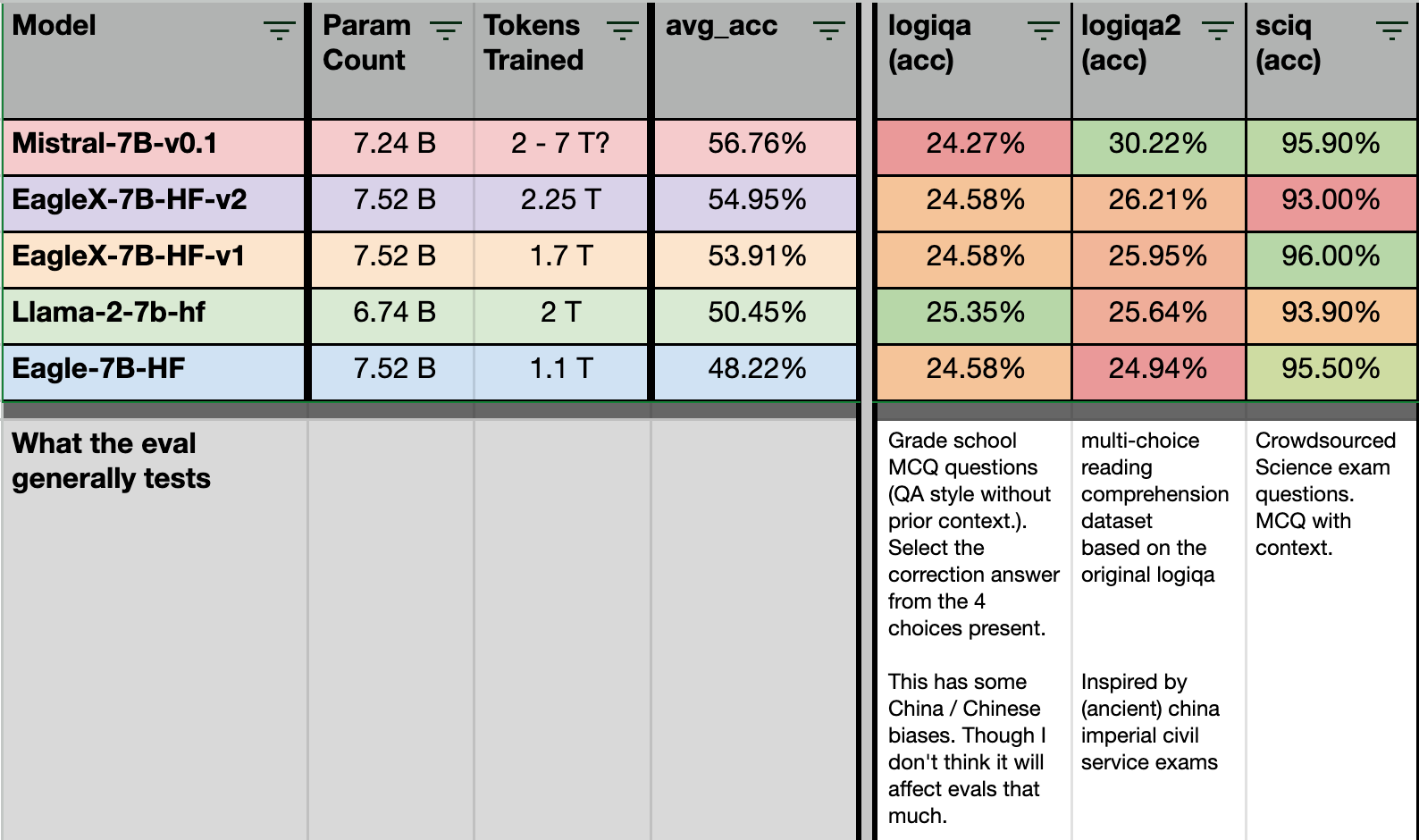
For logiqa, we have very similar evals with 2 major variants. The results between EagleX and LLaMA are close enough, that it’s hard to say which model is clearly better between the two for these evals.
Similarly, sciq got slightly worse between 1.7T to 2.25T, but in general, all models are within trading blows of each other at 90%+ scoring.
The “Not too bad“ and the “Really Bad”

These are the evals the EagleX model performs worse when compared to both Mistral and LLaMA. However, for the evals that we’ve lost to LLaMA, it’s typically by a narrow margin.
One major error that occurred in the 1.7T model, was the accidental exclusion of the math dataset, which caused a degradation of math performance.
Since then, we have added back math text and math materials. Which boosted the arithmetic score. However, given the number of tokens between 1.7T and 2.25T, and the learning rate, the increase in math score was limited.
Our recommendation still stands that realistically IMO - no one should be depending on a 7B model for math (just saying)
180 English Evals
As per the previous 1.7T release. let’s zoom out, and look at it holistically across 180 English evals.
You can view the full results here
Although using the overall averages across all the evals does have a bias on the results towards larger eval sets (due to double counting, e.g. mmlu overall and many individual mmlu test), it does not change the ranking among the EagleX, Mistral, LLaMA and the original Eagle models.

However, these results are useful for smaller insights (as per the previous model as well). Such as measuring specifically gaps in knowledge by “subject domain” within the models.
Perhaps a good dataset + Scalable architecture:
is all you need?
The RWKV Open Source Foundation's goal is to ensure AI access is made accessible to everyone in the world, regardless of language or economic status.
In line with our goal, it does repeat the question. If the exact architecture, matter less than the data for the model performance?

If true, perhaps we should seek more efficient and scalable architecture, to increase accessibility for everyone regardless of language or economic status.
All while going beyond the English language, which represents only 17% of the global population.
And reducing the impact on our environment.
What’s next for the RWKV group?
This release marks the final release of the Eagle line of RWKV models. With the finalization of the v6 architecture as outlined in the paper here - https://arxiv.org/abs/2404.05892
Our next step is to move onto the v6 Finch line of architecture, which we expect to bring an incremental improvement on the v5 Eagle architecture.
This is made in consideration, that upcycling from Eagle to Finch line of models works from our existing experiments.
Roadmap
v6 Finch: 0.1B, 1.6B, 3B model release
v6 Finch: 7B, 14B training, this would be an upcycle of the Eagle models
MoE: (approximately) 8 x 22B
Basically newer, better, bigger models - as we keep iterating on our goal to build a multi-lingual GPT4 class model, in open-source space, that can run on commodity hardware.
And ensure AI is accessible to everyone, regardless of language, or economic status.
Acknowledgment
We are grateful and would like to thank the following key groups:
Recursal.ai team for financing the GPU resources, and managing the training of this foundation model - you can run the Eagle line of RWKV models on their cloud / on-premise platform today.
EleutherAI for their support, especially in the v5/v6 Eagle/Finch paper
Linux Foundation AI & Data group for supporting and hosting the RWKV project
Along with the various developers, working on the growing collection of RWKV-related projects.